 Peter Smith
Peter Smith

⬤ A fresh benchmark comparison of agentic AI systems puts DeepWriter at the top with an HLE score designed to measure higher-level reasoning, autonomy, and sustained task execution. The chart stacks up several widely used agentic tools, and DeepWriter comes out on top with an HLE score of 50.91—the highest in the field. These results show how certain agentic models are starting to pull ahead when it comes to tasks demanding depth, coherence, and long-form output.
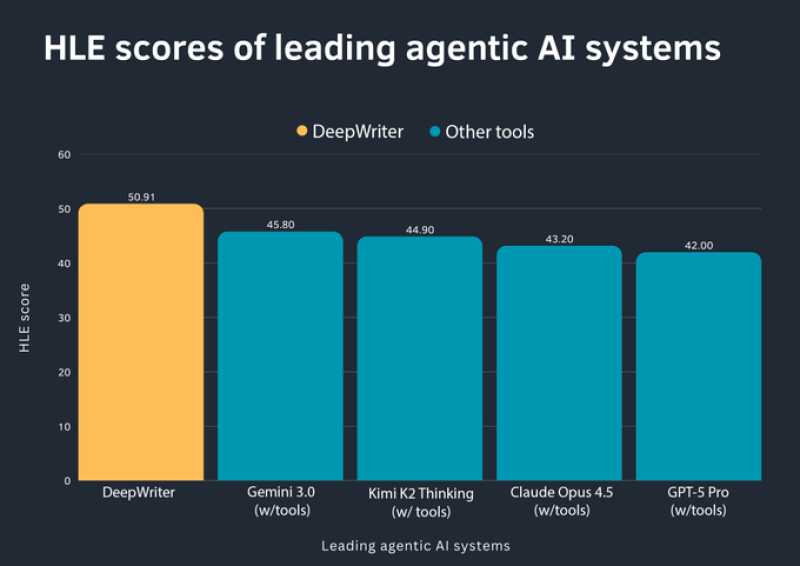
⬤ Looking at the numbers, Gemini 3.0 with tools grabs second place at 45.80, with Kimi K2 Thinking with tools right behind at 44.90. Claude Opus 4.5 with tools lands at 43.20, while GPT-5 Pro with tools posts 42.00. Most competitors cluster pretty tightly together, but DeepWriter's lead stands out—that five-plus point gap between first and second place is the real story here.
⬤ The benchmark zeroes in on agentic performance specifically—how well AI systems handle long-form coherence, tool usage, and multi-step reasoning over extended tasks. The chart visually sets DeepWriter apart from other tools, backing up its higher HLE score. This tracks with what we've seen about DeepWriter excelling in sustained writing and research work, exactly where a lot of general-purpose AI tends to fall apart when tasks get longer and more complex.

⬤ Agentic AI systems are increasingly judged on their ability to handle complex, long-duration work instead of just quick, single-response prompts. Higher HLE scores point to stronger performance in deep research, structured writing, and autonomous task execution. As benchmarks focusing on agentic capability become more important, gaps like these could shape how organizations pick AI tools for knowledge-heavy use cases. The results highlight a bigger shift in AI evaluation—toward endurance, coherence, and reasoning depth as the real measures of progress.
 Peter Smith
Peter Smith


