 Eseandre Mordi
Eseandre Mordi

⬤ Here's the basic idea: a neural network trains for ages with barely any improvement on validation tests, even though it's getting better at memorizing its training data. Then out of nowhere, within a pretty short window, the model flips a switch and starts generalizing properly to stuff it's never seen before. This delayed breakthrough has become a big deal for understanding how modern AI—including large language models—actually learns things.
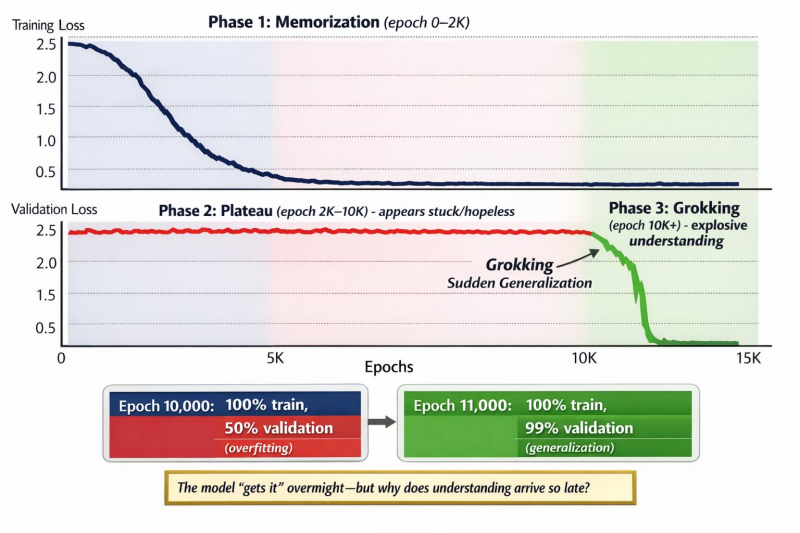
⬤ The process breaks down into three clear phases. Phase 1: Memorization (up to around 2,000 epochs) shows training loss dropping steadily while validation loss stays high—the model's just cramming facts. Phase 2: Plateau (roughly 2,000–10,000 epochs) looks totally stuck. The model keeps overfitting its training data while validation performance barely budges. Phase 3: Grokking (beyond 10,000 epochs) is when validation loss suddenly crashes. The model shifts from rote memorization to actual understanding. In DeepMind's example, validation accuracy rockets from about 50% to nearly 99% in just 1,000 epochs.
⬤ This pattern suggests models might need way longer training—or completely different training approaches—before real generalization kicks in. What used to look like wasted compute or a failed training run might actually be the calm before a learning breakthrough. The finding matters more and more as neural networks get bigger, more complex, and take longer to train.

The conversation around Grokking is heating up as DeepMind—part of Alphabet (NASDAQ: GOOGL)—keeps pushing research into how AI models actually behave under the hood. Realizing that learning doesn't follow a smooth or predictable curve could reshape how teams approach training strategies, set expectations for performance gains, and understand how AI systems absorb structure and reasoning over time. Bottom line: sometimes the best learning happens after what looks like nothing's working at all.
 Eseandre Mordi
Eseandre Mordi


