 Sergey Diakov
Sergey Diakov

⬤ Recent benchmarking data from METR shows just how quickly AI language models are getting better at handling complex software work without human help. The latest numbers reveal that Claude Opus 4.5, which launched in November 2025, can complete tasks that would normally take human engineers around 4 hours and 49 minutes. That's at the 50 percent success mark, meaning the model has a coin-flip chance of finishing the job. The confidence interval ranges pretty wide—from just under 2 hours to over 20 hours—with an average success rate hitting 75 percent.
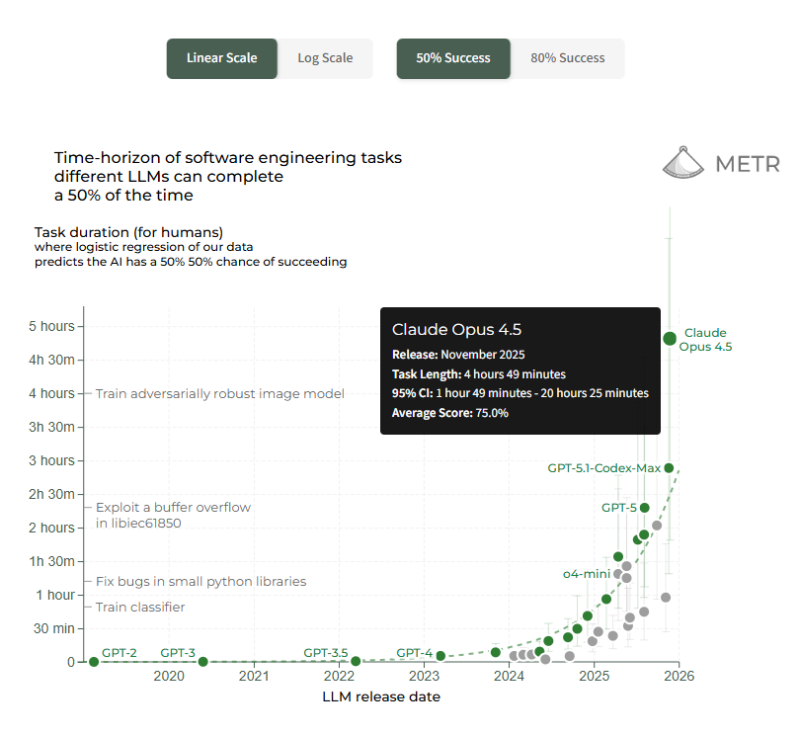
⬤ What's really interesting is how newer models like GPT-5 and GPT-5.1-Codex-Max are closing in on that multi-hour sweet spot, while older systems like GPT-2, GPT-3, and even GPT-4 are still stuck handling much shorter tasks. These benchmarks aren't toy problems either—they include real-world engineering challenges like debugging libraries, patching security exploits, training classifiers, and building machine-learning tools. The 50 percent threshold gives researchers a solid way to measure how reliably models can tackle increasingly complex work.
⬤ Here's where it gets wild: some AI agent workflows are already running autonomously for more than 10 hours straight. The data suggests that the length of tasks these models can handle has been doubling roughly every 7 months, though recent progress looks more like every 4 to 5 months. That acceleration is pretty clear when you look at the trend line showing how each new model release pushes the capability envelope higher.

⬤ Why does this matter? Multi-hour task completion has been a major goalpost for AI autonomy in software development for years. As these systems prove they can reliably handle longer, more complex work, we're seeing expectations shift fast around productivity tools, automation workflows, and what role AI will play in enterprise and developer environments going forward.
 Sergey Diakov
Sergey Diakov


