 Eseandre Mordi
Eseandre Mordi

⬤ GLM-4.7 is now the leading open-weights model on Artificial Analysis's GDPval-AA leaderboard, scoring 1224 ELO in independent testing. The benchmark puts models through real work scenarios—think building presentations or running terminal analysis with web access—then uses an automated system to compare outputs and calculate ELO rankings. Developed by Zai, GLM-4.7 now sits right behind GPT-5.1 (high), showing major progress from earlier releases.
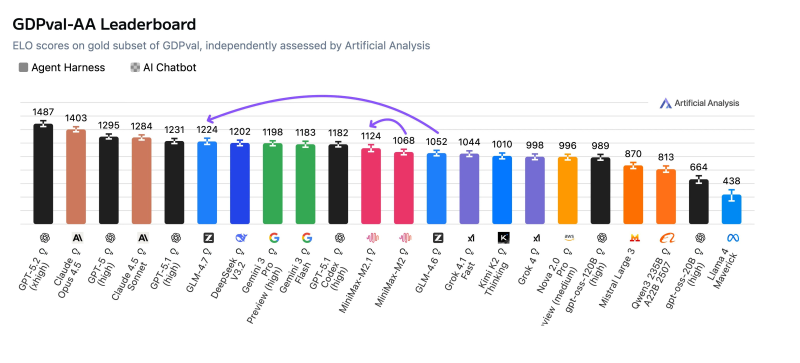
⬤ The 170-point ELO jump from GLM-4.6 to GLM-4.7 is substantial. In practical terms, GLM-4.7 would likely beat its predecessor in about 73% of head-to-head comparisons. That 1224 score puts it ahead of several established models and makes it the top open-weights option on a leaderboard that prioritizes practical performance over synthetic prompt responses.

⬤ MiniMax's M2.1 also made notable gains, adding 56 ELO points over the earlier M2 version. It now slots between GLM-4.6 and GPT-5.1 Codex (high). While M2.1 still trails GLM-4.7, the improvement shows MiniMax is steadily pushing its capabilities forward.
⬤ What makes this leaderboard update interesting is its focus on real-world task performance rather than narrow benchmark tests. The gains from GLM-4.7 and MiniMax M2.1 signal continuing progress in practical AI output quality—developments that could shift competitive dynamics and adoption patterns across the AI landscape.
 Eseandre Mordi
Eseandre Mordi


