 Saad Ullah
Saad Ullah

⬤ OpenAI's GPT-5.2 Pro just claimed the number one spot on FrontierMath's public leaderboard, correctly solving 14 out of 48 problems for a 29.2% accuracy rate. This benchmark is widely recognized as one of the hardest tests for advanced mathematical reasoning in AI, making GPT-5.2 Pro's lead particularly impressive. The model outperformed every other system tested on the same challenging problem set.
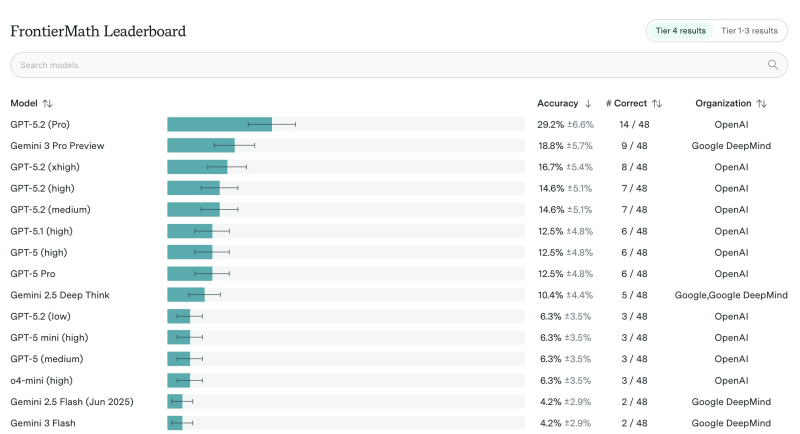
⬤ Coming in second was Gemini 3 Pro Preview at 18.8% accuracy (9 correct answers out of 48). Other GPT-5.2 variations followed close behind—the "xhigh" configuration hit 16.7%, while both "high" and "medium" versions tied at 14.6%. Earlier GPT-5.1 (high) and GPT-5 (high) models each scored 12.5%. What really stands out here is that even the best-performing model solved less than a third of the problems, showing just how brutally difficult FrontierMath really is and how much room there still is for improvement in AI math skills.
⬤ The leaderboard also shows strong competition across the AI industry. Google DeepMind's Gemini 2.5 Deep Think scored 10.4%, while various GPT-5 family models ranged from 6.3% to 12.5%. Gemini 2.5 Flash and Gemini 3 Flash landed near the bottom at 4.2% each. Every score comes with an uncertainty range due to the small 48-question sample size. FrontierMath is classified as a Tier 4 benchmark, meaning it focuses on complex, high-level reasoning rather than straightforward computational tasks.

⬤ This leaderboard update matters because it shows real, measurable progress on genuinely difficult math problems—not just cherry-picked examples or easy prompts. GPT-5.2 Pro's strong performance signals meaningful advances in mathematical reasoning, which could shake up the competitive landscape and raise the bar for what we expect from next-generation AI systems.
 Saad Ullah
Saad Ullah


