 Eseandre Mordi
Eseandre Mordi

⬤ MiniMax's large language model is turning heads with incredibly fast performance when running on local hardware instead of cloud servers. A recent test showed the MiniMax-M2 AWQ 4-bit model running across eight RTX 3090 GPUs (24GB each) hitting an impressive 918 milliseconds for Time-to-First-Token (TTFT). The system pushed out 97.5 tokens per second at peak generation and handled prefill throughput of 975.1 tokens per second, showing it can keep up with real-time interactive use.
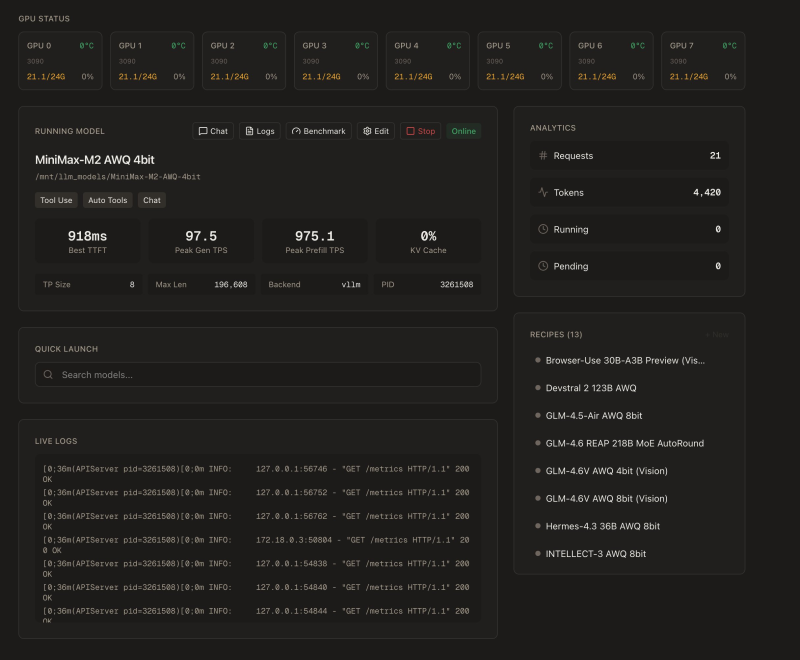
⬤ The dashboard tracked 21 total requests and generated 4,420 tokens during testing. The setup included TP Size 8, a maximum length of 196,608 tokens, and ran on a vLLM backend. The interface showed multiple AI model configurations ready to go, suggesting this environment was built specifically for serious local inference work. Users are calling MiniMax "blazing fast on local hardware," claiming few alternatives can match this performance under similar conditions.
⬤ This demonstration shows how AI performance that used to require massive cloud infrastructure is now possible on local GPU setups. Running MiniMax locally means faster deployment, better data privacy, and lower latency for apps that need instant responses. Getting sub-second TTFT and high streaming speeds on consumer-grade GPUs is a big deal for developers working with on-premise AI systems.

⬤ As models like MiniMax keep pushing inference speed and hardware efficiency forward, high-performance local AI is becoming more accessible across enterprise, research, and hobbyist spaces. The performance numbers here prove that optimization and quantization techniques are closing the gap between cloud and local systems, making AI infrastructure more flexible and competitive.
 Eseandre Mordi
Eseandre Mordi


