 Saad Ullah
Saad Ullah

⬤ Nvidia (NASDAQ: NVDA) just grabbed attention again with new performance numbers showing its Blackwell GB300 NVL72 crushing Google's Ironwood TPU on mixture-of-experts (MoE) AI training tasks. According to data shared on LinkedIn, Nvidia's hardware is pulling ahead by as much as 1.9× in throughput per chip on demanding training jobs—a sign that its integrated approach to silicon, networking, and software might be paying off in ways raw specs don't capture.
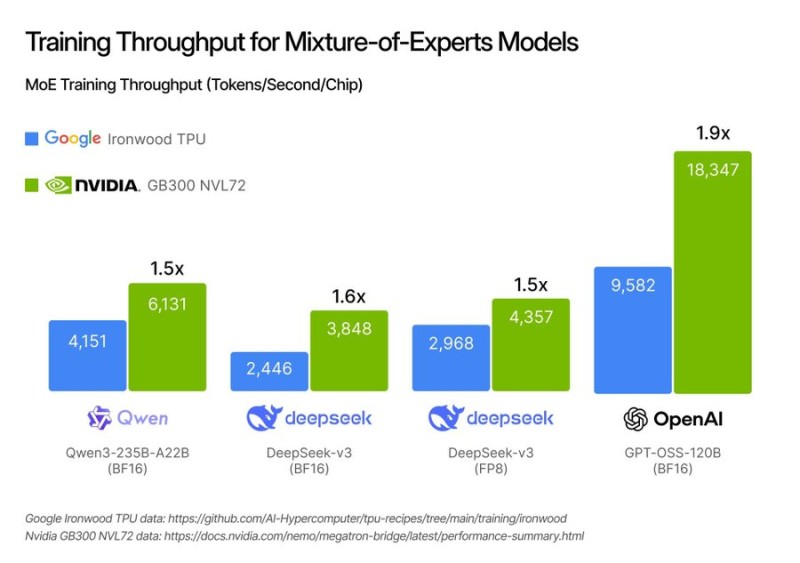
⬤ The comparison looked at MoE training speed across several major models, measured in tokens processed per second per chip. On Qwen's Qwen3-235B-A22B model using BF16 precision, Google's Ironwood hit 4,151 tokens per second while Nvidia's GB300 reached 6,131—a 1.5× jump. DeepSeek-v3 in BF16 went from 2,446 tokens per second on Ironwood to 3,848 on Blackwell, a 1.6× gain. The FP8 version of the same model showed a 1.5× boost, moving from 2,968 to 4,357 tokens per second. The biggest gap showed up on OpenAI's GPT-OSS-120B in BF16, where Ironwood managed 9,582 tokens per second but Nvidia nearly doubled it at 18,347—hitting that 1.9× mark.
⬤ What these numbers suggest is that FLOPS alone don't tell the full story. Memory bandwidth, how fast data moves around, and how well chips sync up across massive clusters seem to matter just as much—especially when scaling up MoE architectures. The analysis points out that Nvidia's networking and system-level design might be doing heavy lifting behind the scenes, giving it an edge that goes beyond what spec sheets advertise.
⬤ This matters because Nvidia still owns the AI chip market, and results like these could help justify that dominance even as competition heats up from cloud giants and alternative chipmakers. If Blackwell keeps proving itself on real workloads instead of just benchmarks, it strengthens Nvidia's case in the AI compute race and gives investors another reason to stay confident in NVDA stock.
 Saad Ullah
Saad Ullah


