 Peter Smith
Peter Smith

⬤ OpenAI just dropped GPT-5.1-Codex-Max, its latest frontier agentic coding model designed to handle long-horizon and multi-context development work. The system brings faster performance, sharper intelligence, and notably better token efficiency, letting it tackle complex software tasks autonomously for hours at a time. The model is already live across Codex in the CLI, IDE integrations, and cloud environments, with API access coming soon.
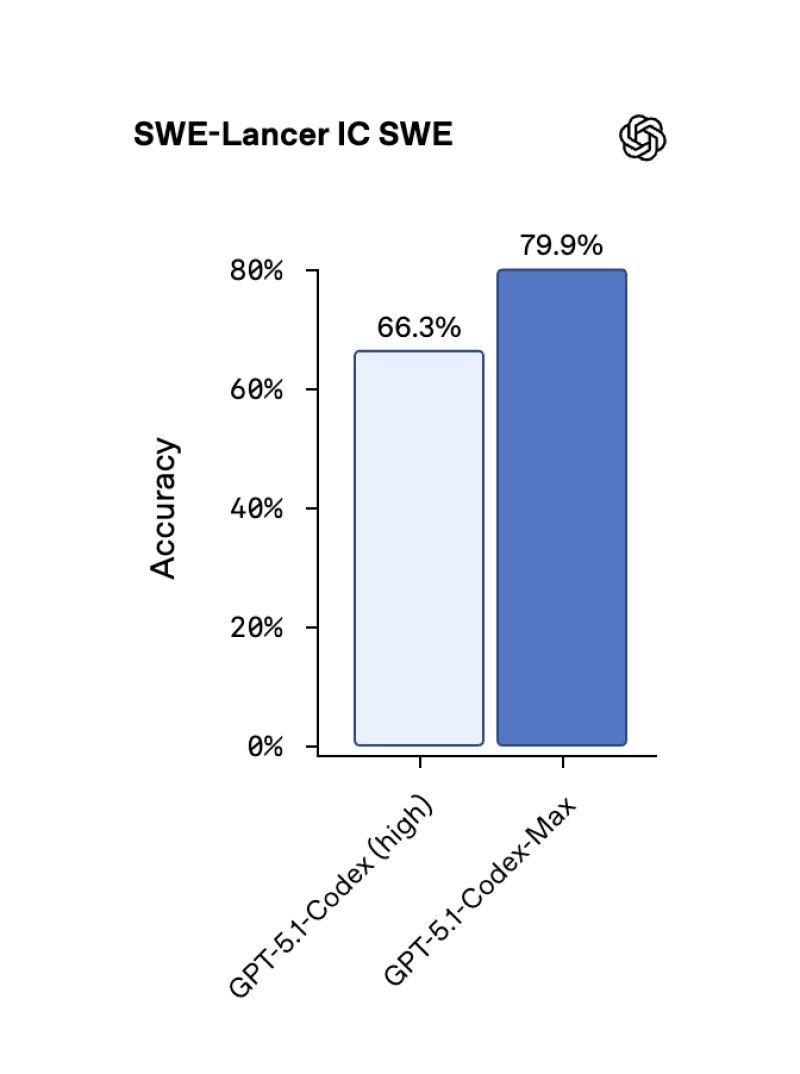
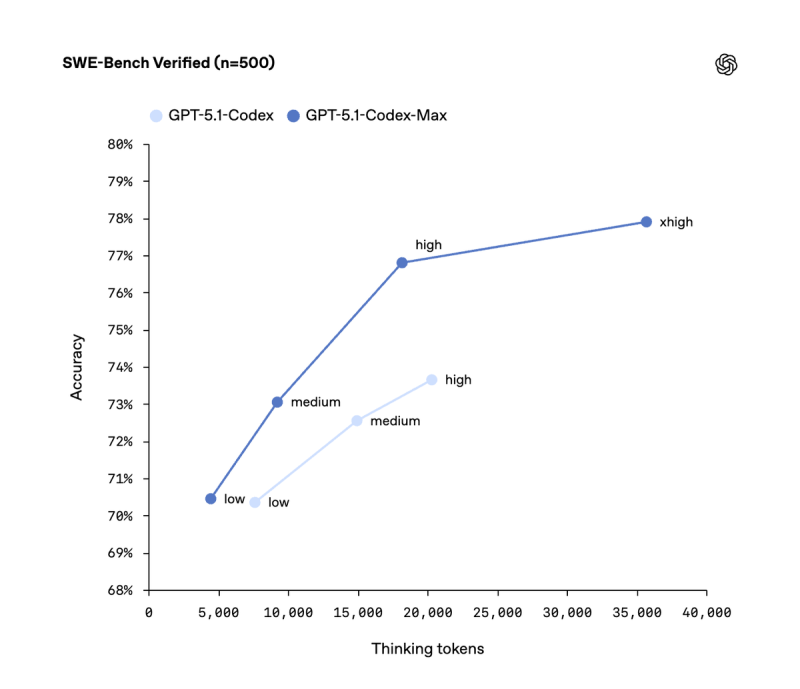
⬤ Benchmark results reveal GPT-5.1-Codex-Max beats earlier Codex versions across major engineering tests. On SWE-Lancer IC SWE, accuracy jumped from 66.3% to 79.9%. Terminal Bench 2.0 scores climbed from 52.8% to 58.1%. Performance on SWE-Bench Verified also shows steady gains across different thinking-token levels, pointing to stronger reasoning and better planning capabilities. OpenAI's internal teams are now shipping 70% more pull requests using the new model, demonstrating real productivity gains in everyday workflows.
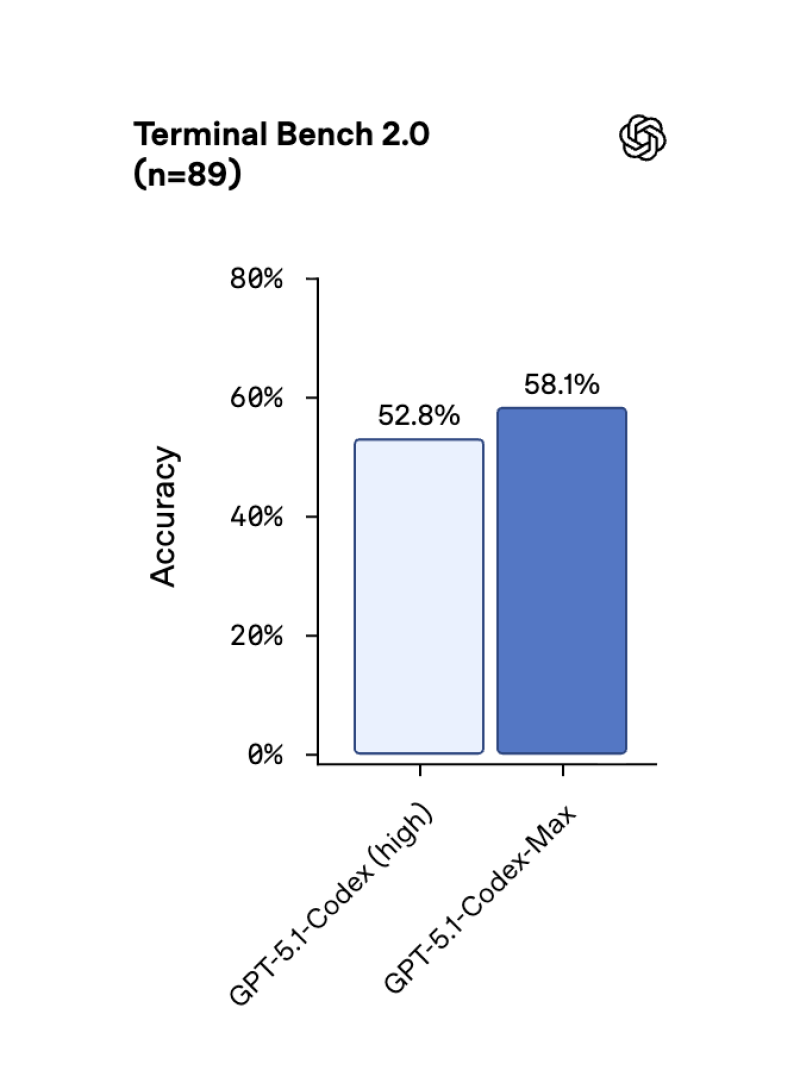
⬤ The model handles long-duration autonomy remarkably well, working for several hours—sometimes over 24 hours—on deep debugging, large-scale refactors, and command-line automation. GPT-5.1-Codex-Max is roughly 30% more token-efficient than its predecessor, making it more practical for extended development sessions. Performance charts show clear accuracy improvements across all test sets, highlighting the benefits of expanded token windows and internal optimization designed for persistent coding work.
⬤ The GPT-5.1-Codex-Max launch highlights how quickly agentic coding systems are evolving and their growing role in automating complex software engineering tasks. With major gains in accuracy, efficiency, and long-horizon performance, the model strengthens AI's place in modern development pipelines and signals a wider move toward scalable, autonomous coding across tech organizations.
 Peter Smith
Peter Smith


